Supervised Learning là gì? Mô hình qua dữ liệu có nhãn
Supervised Learning là gì? Trong kỷ nguyên công nghệ 4.0, học máy có giám sát (Supervised Learning) là trái tim của trí tuệ nhân tạo, cho phép máy tính học từ dữ liệu có nhãn để dự đoán và phân loại chính xác.
Cùng tìm hiểu chi tiết về Supervised Learning qua bài viết dưới đây.
Supervised Learning là gì?
Supervised Learning hay học máy có giám sát, là một nhánh quan trọng của học máy (machine learning) trong trí tuệ nhân tạo (AI).

Trong phương pháp này, mô hình được huấn luyện trên một tập dữ liệu đã được gắn nhãn, tức là mỗi mẫu dữ liệu đầu vào đi kèm với một đầu ra mong muốn.
Mục tiêu của Supervised Learning là giúp mô hình học cách ánh xạ từ đầu vào (input) sang đầu ra (output) chính xác dựa trên các ví dụ đã được cung cấp.
Ví dụ: trong bài toán nhận diện hình ảnh, nếu bạn muốn mô hình phân biệt ảnh chó và mèo, tập dữ liệu huấn luyện sẽ bao gồm các hình ảnh được gắn nhãn “chó” hoặc “mèo”.
Mô hình sẽ học các đặc điểm từ dữ liệu này để dự đoán nhãn cho các hình ảnh mới.
Cách hoạt động của Supervised Learning bao gồm:
- Đầu vào là tập dữ liệu gồm các cặp (đặc trưng, nhãn).
- Thuật toán học tìm cách ánh xạ từ đặc trưng sang nhãn.
- Mô hình được đánh giá bằng cách so sánh dự đoán với nhãn thực tế.
- Mục tiêu là tối ưu hóa mô hình để dự đoán chính xác với dữ liệu chưa từng thấy.
Cách thức hoạt động của Supervised Learning
Quá trình Supervised Learning có thể được tóm tắt qua các bước chính sau:

– Thu thập dữ liệu có nhãn: Dữ liệu huấn luyện bao gồm các ví dụ đã được gán nhãn. Ví dụ, trong bài toán phân loại email spam, mỗi email được dán nhãn “spam” hoặc “không spam”.
– Tiền xử lý dữ liệu: Dữ liệu được làm sạch, chuẩn hóa hoặc chuyển đổi thành dạng số để máy tính có thể xử lý.
– Chọn thuật toán học máy phù hợp: Một số thuật toán phổ biến như Hồi quy tuyến tính (Linear Regression), Cây quyết định (Decision Tree), Mạng nơ-ron (Neural Network), Máy vector hỗ trợ (SVM)…
– Huấn luyện mô hình: Thuật toán sử dụng dữ liệu huấn luyện để tìm ra quy luật ánh xạ từ đặc trưng sang nhãn.
– Đánh giá mô hình: Sử dụng tập dữ liệu kiểm thử (test set) để kiểm tra hiệu suất dự đoán, tính toán các chỉ số như độ chính xác (accuracy), độ nhạy (recall), độ đặc hiệu (precision)…
– Triển khai mô hình: Sau khi mô hình đủ tốt, nó được áp dụng vào dữ liệu thực tế để dự đoán, phân loại.
So sánh Supervised Learning với các phương pháp học máy khác
Để hiểu rõ hơn Supervised Learning là gì, hãy so sánh nó với các phương pháp học máy khác:
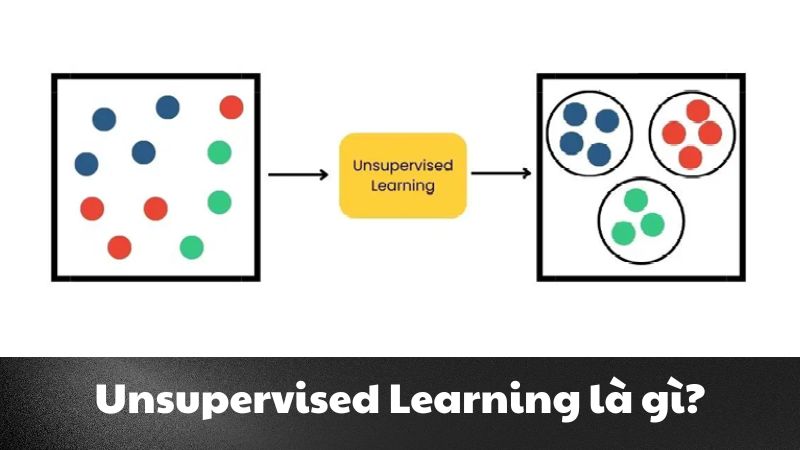
– UnSupervised Learning:
- Không sử dụng dữ liệu có nhãn.
- Mục tiêu: Tìm cấu trúc ẩn trong dữ liệu, như phân cụm (clustering) hoặc giảm chiều (dimensionality reduction).
- Ví dụ: Phân nhóm khách hàng dựa trên hành vi mua sắm.
– Reinforcement Learning:
- Mô hình học qua thử và sai, nhận phần thưởng hoặc hình phạt dựa trên hành động.
- Ví dụ: Huấn luyện robot tự di chuyển trong môi trường.
Supervised Learning nổi bật nhờ khả năng dự đoán chính xác khi có dữ liệu chất lượng, nhưng nó yêu cầu đầu tư vào dữ liệu có nhãn, không giống như các phương pháp trên.
Những thách thức và hạn chế của Supervised Learning
Mặc dù Supervised Learning rất phổ biến và hiệu quả, phương pháp này vẫn tồn tại một số hạn chế nhất định:

- Việc thu thập và gán nhãn dữ liệu tốn kém thời gian và chi phí, đặc biệt với dữ liệu lớn.
- Mô hình có thể học quá mức (overfitting) với dữ liệu huấn luyện mà không áp dụng tốt cho dữ liệu mới.
- Dữ liệu sai lệch, không đầy đủ hoặc nhiễu có thể làm giảm hiệu quả mô hình.
- Trong nhiều lĩnh vực, dữ liệu chưa gán nhãn chiếm phần lớn, gây khó khăn cho việc áp dụng Supervised Learning.
Các thuật toán Supervised Learning phổ biến
Dưới đây là một số thuật toán nổi bật thường được sử dụng trong Supervised Learning, kèm theo mô tả chi tiết hơn:

- Hồi quy tuyến tính (Linear Regression)
Đây là thuật toán dự đoán giá trị liên tục dựa trên mối quan hệ tuyến tính giữa các biến đầu vào và biến đầu ra.
Ví dụ phổ biến là dự đoán giá nhà dựa trên diện tích, vị trí hoặc các yếu tố khác.
- Hồi quy logistic (Logistic Regression)
Thuật toán này dùng để giải quyết bài toán phân loại nhị phân, bằng cách ước lượng xác suất một mẫu thuộc về một lớp cụ thể.
Thuật toán thường được áp dụng trong phân loại email spam hay không spam, hoặc xác định bệnh nhân có mắc bệnh hay không.
- Cây quyết định (Decision Tree)
Thuật toán này xây dựng mô hình dựa trên cấu trúc cây gồm các câu hỏi phân nhánh để phân loại hoặc dự đoán.
Ưu điểm là dễ hiểu, trực quan và có thể xử lý cả dữ liệu phân loại và số liệu.
- Máy vector hỗ trợ (SVM – Support Vector Machine)
SVM tìm siêu phẳng tốt nhất để phân tách dữ liệu thuộc các lớp khác nhau, tối ưu hóa khoảng cách đến các điểm dữ liệu gần nhất.
Máy vector hỗ trợ đặc biệt hiệu quả với dữ liệu nhiều chiều và có khả năng phân loại phi tuyến khi sử dụng hàm nhân (kernel).
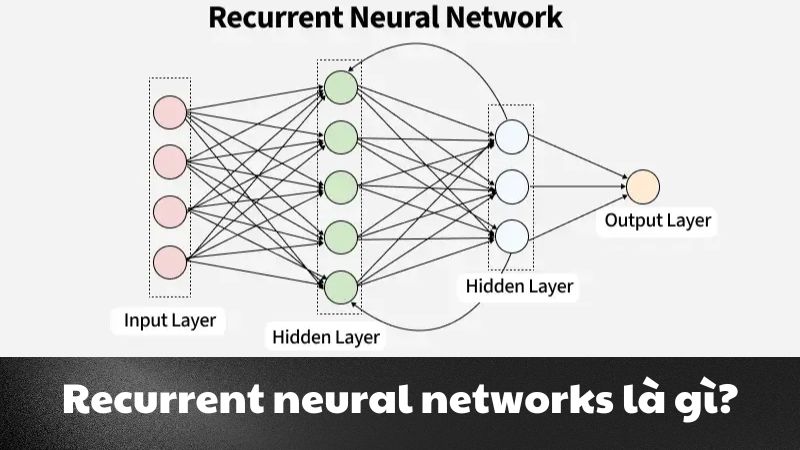
- Mạng nơ-ron (Neural Networks)
Mạng nơ-ron nhân tạo mô phỏng cấu trúc não người với các tầng neuron liên kết, có khả năng học các mẫu phức tạp trong dữ liệu lớn.
Mạng nơ-ron được ứng dụng rộng rãi trong nhận dạng hình ảnh, xử lý giọng nói và nhiều lĩnh vực AI hiện đại khác.
Kết luận
Supervised Learning là gì? Đó là phương pháp học máy cốt lõi, sử dụng dữ liệu có nhãn để dự đoán và phân loại.
Với vai trò quan trọng trong AI,Supervised Learning đang định hình tương lai công nghệ, dù vẫn còn thách thức về dữ liệu và chi phí.