
Recurrent neural networks là gì? Học máy chuỗi hóa
Khi bạn nhập văn bản vào điện thoại và nó tự động gợi ý từ tiếp theo, hay khi Netflix đề xuất bộ phim mới phù hợp gu bạn, đó là nhờ vào một trong những công nghệ đột phá nhất trong trí tuệ nhân tạo: Recurrent Neural Networks (RNN).
Không chỉ dừng lại ở xử lý chuỗi, Recurrent Neural Networks là gì còn là chìa khóa trong việc khai thác dữ liệu có tính tuần tự, mở ra kỷ nguyên mới cho các ứng dụng học sâu và ngôn ngữ tự nhiên.
Recurrent neural networks là gì?
Recurrent Neural Networks (RNN) là một kiến trúc mạng nơ-ron nhân tạo đặc biệt chuyên dùng để xử lý dữ liệu tuần tự, dữ liệu có tính liên kết theo chuỗi như văn bản, âm thanh, thời gian.
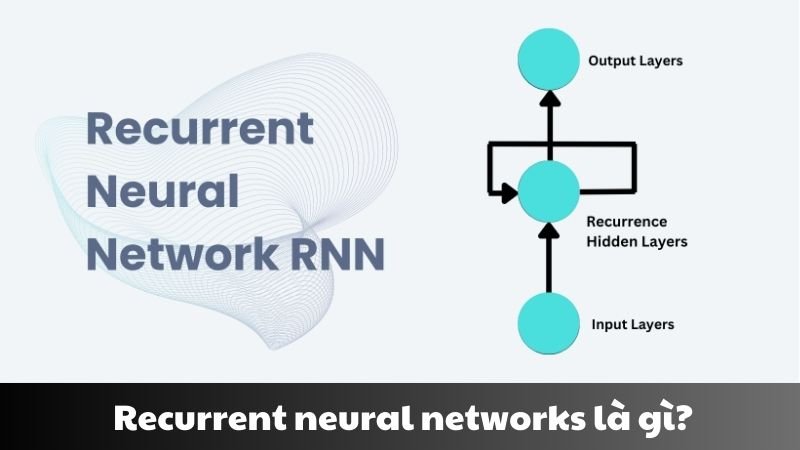
Không giống như các mạng nơ-ron truyền thống (Feedforward Neural Networks), RNN có khả năng ghi nhớ thông tin từ các bước trước đó nhờ vào một cơ chế gọi là vòng lặp hồi tiếp (recurrence).
Mỗi bước trong chuỗi đầu vào được xử lý không chỉ dựa trên dữ liệu hiện tại, mà còn dựa vào trạng thái ẩn (hidden state) biểu diễn nội dung từ quá khứ.
Điều này giúp RNN đặc biệt mạnh mẽ trong các bài toán cần hiểu ngữ cảnh, thứ tự hoặc lịch sử.
Chẳng hạn như dịch máy, phân tích cảm xúc, nhận dạng giọng nói, hoặc dự đoán chuỗi thời gian.
Cơ chế hoạt động của RNN: Ghi nhớ trạng thái tuần tự trong chuỗi dữ liệu
Recurrent Neural Networks (RNN) là một loại mạng nơ-ron sâu chuyên xử lý dữ liệu tuần tự bằng cách duy trì trạng thái ẩn có tính liên tục theo thời gian.
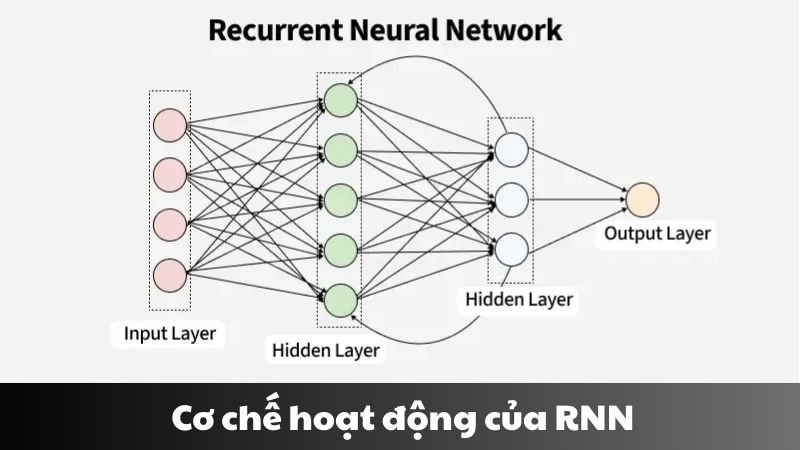
Cơ chế hoạt động chính gồm:
- Input được xử lý theo từng timestep: 𝑥1, 𝑥2, 𝑥3,…
- Tại mỗi timestep, mạng tạo ra một trạng thái ẩn (hidden state) – như một bộ nhớ tạm.
- Trạng thái ẩn này được chuyển tiếp, giúp mạng ghi nhớ những gì đã xảy ra trước đó.
- Dựa trên trạng thái hiện tại và thông tin mới, mạng đưa ra dự đoán hoặc phản hồi.
Nhờ khả năng lưu trữ và cập nhật trạng thái theo chuỗi thời gian, RNN được ứng dụng mạnh trong NLP, speech recognition, time-series prediction và các bài toán xử lý dữ liệu tuần tự phức tạp.
Những thách thức khi huấn luyện RNN truyền thống
Mặc dù Recurrent Neural Networks (RNN) có thể xử lý dữ liệu tuần tự và lưu trữ trạng thái theo thời gian, nhưng khi chuỗi dữ liệu trở nên dài, mô hình bắt đầu gặp vấn đề nghiêm trọng:
Vanishing Gradient – Gradient tiêu biến
Khi huấn luyện bằng thuật toán backpropagation through time (BPTT), các gradient được nhân liên tục qua nhiều bước thời gian.
Nếu giá trị gradient nhỏ hơn 1, chúng sẽ giảm dần về gần 0 sau nhiều lần nhân, khiến các lớp đầu tiên gần như không học được gì.
Kết quả: RNN mất khả năng ghi nhớ thông tin dài hạn, chỉ học được các mối quan hệ ngắn.
Exploding Gradient – Gradient bùng nổ
Ngược lại, nếu gradient lớn hơn 1, việc nhân liên tục khiến chúng phóng đại quá mức, dẫn đến giá trị trọng số tăng đột biến.
Điều này gây ra hiện tượng mô hình không ổn định, dẫn đến mất hội tụ hoặc NaN trong quá trình huấn luyện.
LSTM và GRU – Giải pháp tối ưu cho “học” dài hạn
Để giải quyết các vấn đề trên, các kiến trúc RNN cải tiến đã ra đời với mục tiêu giữ được thông tin dài hạn mà vẫn duy trì tính ổn định khi huấn luyện.
LSTM – Long Short-Term Memory
LSTM được thiết kế với một cơ chế bộ nhớ có kiểm soát thông qua ba loại “gate”:
Forget Gate: Cho biết thông tin nào trong bộ nhớ cần bị xóa.
Input Gate: Xác định thông tin mới nào sẽ được lưu vào bộ nhớ.
Output Gate: Điều khiển thông tin nào sẽ được xuất ra làm đầu ra và cập nhật trạng thái ẩn.
Nhờ đó LSTM có thể lưu trữ hoặc quên thông tin một cách có chọn lọc, giúp mô hình học tốt các phụ thuộc dài hạn mà RNN truyền thống bỏ sót.
GRU – Gated Recurrent Unit
GRU là một biến thể gọn nhẹ hơn của LSTM, với hai gate chính:
Reset Gate: Giúp mô hình quên bớt thông tin cũ không cần thiết.
Update Gate: Kiểm soát mức độ lưu trữ thông tin mới và giữ lại trạng thái trước đó.
GRU đơn giản hơn LSTM (ít tham số hơn), do đó tốc độ huấn luyện nhanh hơn trong khi vẫn giữ hiệu quả tương đương trong nhiều tác vụ.
So sánh RNN với các mạng nơ-ron khác
| Tiêu chí | RNN (Recurrent Neural Network) | CNN (Convolutional Neural Network) | Transformer |
| Dữ liệu đầu vào phù hợp | Dữ liệu tuần tự (text, speech, time-series) | Dữ liệu không gian (ảnh, video, tín hiệu 2D) | Dữ liệu tuần tự (text, audio, image patch, embedding) |
| Cách xử lý dữ liệu | Tuần tự từng bước (timestep) | Xử lý cục bộ theo vùng (convolution) | Xử lý toàn cục bằng self-attention |
| Khả năng nhớ ngữ cảnh dài | Kém với RNN thường, tốt với LSTM/GRU | Không có khả năng ghi nhớ thời gian | Xuất sắc, do cơ chế attention không bị giới hạn độ dài |
| Tính song song | Thấp, vì phụ thuộc trạng thái trước | Cao – các tầng tích chập có thể xử lý đồng thời | Rất cao – không phụ thuộc tuần tự, dễ parallel hóa |
| Vấn đề gradient | Dễ bị vanishing/exploding gradient | Ít gặp vấn đề | Không gặp vấn đề lớn về gradient |
| Độ phức tạp tính toán | Trung bình – tăng theo độ dài chuỗi | Thấp – tối ưu tốt trên ảnh | Cao – đặc biệt với chuỗi dài (quadratic complexity) |
| Yêu cầu tài nguyên | Thấp đến vừa phải | Tối ưu tốt trên GPU | Cao – cần nhiều RAM/GPU, đặc biệt với mô hình lớn |
| Ứng dụng phổ biến | NLP, speech recognition, time-series prediction | Image classification, object detection, video analysis | NLP hiện đại (GPT, BERT), dịch máy, tạo văn bản, AI đa phương thức |
Có thể thấy:
- RNN: Phù hợp xử lý chuỗi ngắn, cần ghi nhớ trạng thái theo thời gian, đơn giản.
- CNN: Mạnh trong xử lý dữ liệu không gian như ảnh/video, ít phù hợp chuỗi.
- Transformer: Là chuẩn mực mới cho AI tuần tự – vượt trội trong NLP và khả năng mở rộng, chính xác cao, học ngữ cảnh tốt.
Kết luận
Recurrent Neural Networks là gì không chỉ là một kiến trúc mạng nơ-ron, mà còn là cầu nối giúp trí tuệ nhân tạo hiểu được thời gian.
Dù bị cạnh tranh bởi các mô hình mới như Transformer, nhưng với tính đơn giản, hiệu quả và sự phù hợp trong nhiều bài toán thực tiễn, RNN vẫn là một phần quan trọng trong hành trình tiến hóa của công nghệ học sâu.


