
Unsupervised Learning là gì? Tìm hiểu về học máy không giám sát
Trong thời đại bùng nổ dữ liệu như hiện nay, Unsupervised Learning (học máy không giám sát) đang trở thành một trong những phương pháp quan trọng nhất trong lĩnh vực trí tuệ nhân tạo.
Nhưng Unsupervised Learning là gì? Bài viết này sẽ giúp bạn hiểu rõ về khái niệm của phương pháp học máy không giám sát.
Unsupervised Learning là gì?
Unsupervised Learning (học máy không giám sát) là một nhánh của học máy, trong đó mô hình được huấn luyện trên dữ liệu không được gán nhãn.
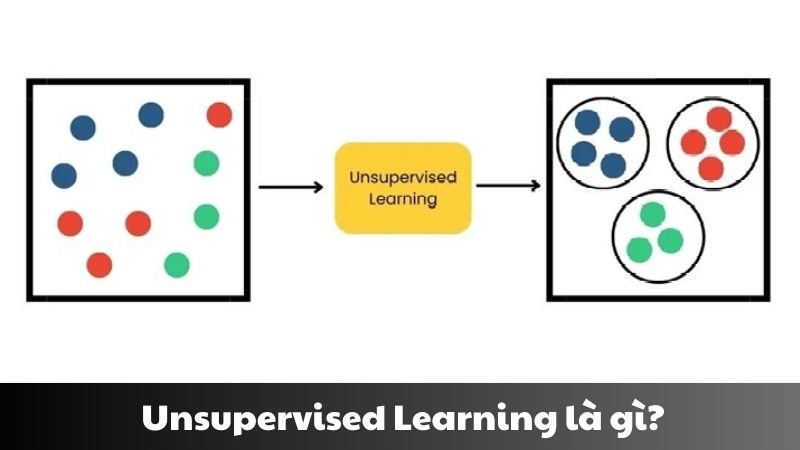
Khác với học có giám sát (Supervised Learning), phương pháp này không yêu cầu dữ liệu đầu vào phải được gán nhãn hoặc phân loại trước.
Thay vào đó nó tìm kiếm các mẫu, cấu trúc hoặc mối quan hệ ẩn trong dữ liệu mà không cần sự hướng dẫn cụ thể.
Trong bối cảnh bùng nổ dữ liệu hiện nay, khi lượng thông tin khổng lồ được tạo ra mỗi ngày, việc gán nhãn cho toàn bộ dữ liệu trở nên không khả thi.
Đây chính là lúc học máy không giám sát phát huy vai trò quan trọng của mình trong công nghệ hiện đại.
Cách hoạt động của học máy không giám sát
Để hiểu rõ hơn về cách hoạt động của học máy không giám sát, chúng ta cần phân tích quy trình cơ bản sau:
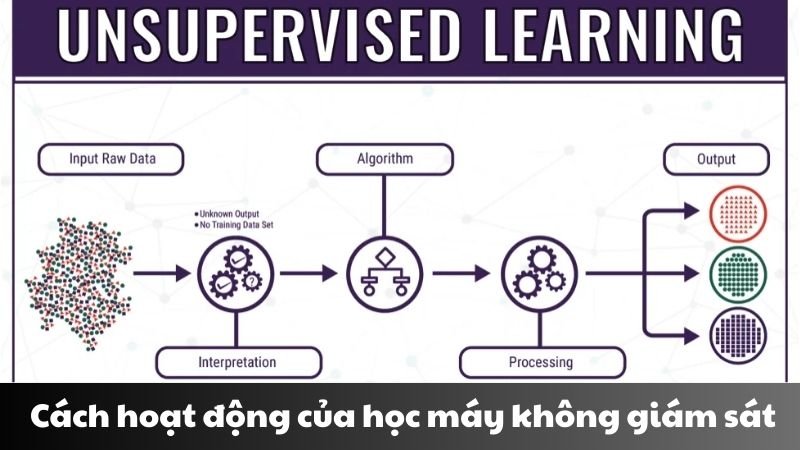
- Thu thập dữ liệu: Hệ thống thu thập dữ liệu không được gán nhãn từ nhiều nguồn khác nhau.
- Tiền xử lý dữ liệu: Dữ liệu được làm sạch, chuẩn hóa và chuyển đổi để phù hợp với thuật toán.
- Áp dụng thuật toán: Các thuật toán học không giám sát được áp dụng để tìm kiếm mẫu, nhóm hoặc mối quan hệ trong dữ liệu.
- Phân tích kết quả: Kết quả được phân tích để rút ra thông tin hữu ích và ý nghĩa.
- Tối ưu hóa mô hình: Dựa trên kết quả phân tích, mô hình được điều chỉnh và tối ưu hóa.
Điểm đặc biệt của học không giám sát là nó có thể phát hiện ra những mẫu hoặc mối quan hệ mà con người có thể bỏ qua, đặc biệt khi làm việc với dữ liệu phức tạp và đa chiều.
Đây là lý do tại sao công nghệ này đang được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau.
Thuật toán Unsupervised Learning phổ biến
Có nhiều thuật toán Unsupervised Learning phổ biến được sử dụng trong thực tế. Dưới đây là một số thuật toán nổi bật:
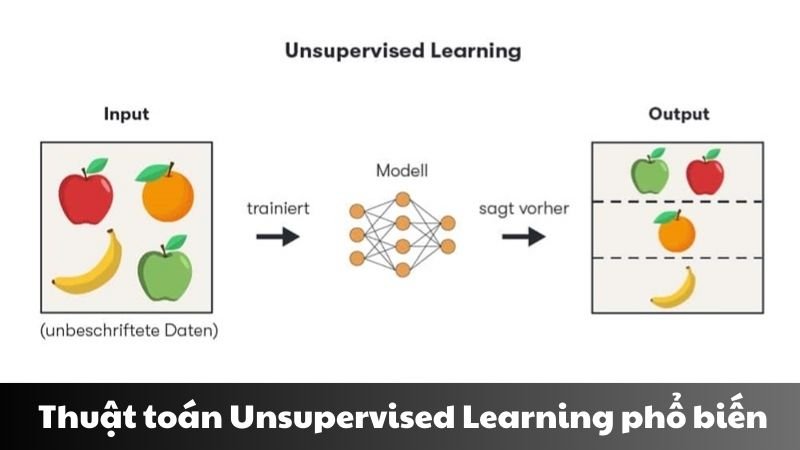
Thuật toán phân cụm (Clustering)
Phân cụm là một trong những kỹ thuật cơ bản nhất của học không giám sát, nhằm nhóm các đối tượng tương tự vào cùng một nhóm (cụm).
Các thuật toán phân cụm phổ biến gồm:
- K-means: Phân chia dữ liệu thành K cụm dựa trên khoảng cách giữa các điểm dữ liệu và tâm cụm.
- Hierarchical Clustering: Xây dựng cây phân cấp các cụm bằng cách hợp nhất hoặc chia tách các cụm hiện có.
- DBSCAN: Phân cụm dựa trên mật độ, có khả năng phát hiện các cụm có hình dạng tùy ý và xử lý nhiễu tốt.
Giảm chiều dữ liệu (Dimensionality Reduction)
Giảm chiều dữ liệu là quá trình giảm số lượng biến ngẫu nhiên bằng cách lấy một tập hợp các biến chính.
Các thuật toán phổ biến:
- Principal Component Analysis (PCA): Chuyển đổi dữ liệu thành một tập hợp các thành phần chính không tương quan.
- t-SNE: Kỹ thuật giảm chiều phi tuyến tính, đặc biệt hiệu quả cho việc trực quan hóa dữ liệu đa chiều.
- Autoencoders: Sử dụng mạng neural để học cách nén và giải nén dữ liệu, giữ lại các đặc trưng quan trọng.
Phát hiện bất thường (Anomaly Detection)
Phát hiện bất thường là quá trình xác định các mẫu hiếm gặp hoặc khác biệt so với hầu hết dữ liệu. Các phương pháp phổ biến:
- Isolation Forest: Cô lập các điểm dữ liệu bất thường bằng cách chia ngẫu nhiên không gian đặc trưng.
- One-Class SVM: Học một biên quyết định xung quanh dữ liệu bình thường và phát hiện các điểm nằm ngoài biên.
- Local Outlier Factor (LOF): So sánh mật độ cục bộ của một điểm với mật độ của các điểm lân cận.
Sự khác biệt giữa Supervised Learning và Unsupervised Learning
Để hiểu rõ hơn về học không giám sát, chúng ta cần phân biệt nó với phương pháp học có giám sát.
Dưới đây là sự khác biệt giữa Supervised Learning và Unsupervised Learning:
| Tiêu chí | Supervised Learning | Unsupervised Learning |
| Dữ liệu đầu vào | Dữ liệu được gán nhãn | Dữ liệu không được gán nhãn |
| Mục tiêu | Dự đoán kết quả dựa trên dữ liệu đã biết | Tìm kiếm mẫu và cấu trúc ẩn trong dữ liệu |
| Phản hồi | Có phản hồi trực tiếp về độ chính xác | Không có phản hồi trực tiếp |
| Ứng dụng | Phân loại, hồi quy | Phân cụm, giảm chiều, phát hiện bất thường |
| Độ phức tạp | Thường đơn giản hơn về mặt khái niệm | Thường phức tạp hơn về mặt khái niệm |
Sự khác biệt cơ bản nhất là trong học có giám sát, mô hình được “dạy” bằng cách cung cấp các ví dụ có nhãn, trong khi học không giám sát phải tự tìm ra cấu trúc từ dữ liệu không có nhãn.
Ứng dụng của Unsupervised Learning trong thực tế
Ứng dụng của Unsupervised Learning trong thực tế rất đa dạng và ngày càng mở rộng theo sự phát triển của công nghệ. Sau đây là một số ứng dụng nổi bật:
– Phân khúc khách hàng trong tiếp thị
Các công ty sử dụng thuật toán phân cụm để phân chia khách hàng thành các nhóm dựa trên hành vi mua sắm, sở thích và đặc điểm nhân khẩu học.
Điều này giúp họ phát triển chiến lược tiếp thị và sản phẩm phù hợp với từng phân khúc.
– Phát hiện gian lận trong dịch vụ tài chính
Các thuật toán phát hiện bất thường được sử dụng để xác định các giao dịch đáng ngờ hoặc bất thường, giúp ngăn chặn gian lận trong lĩnh vực tài chính và ngân hàng.
– Hệ thống đề xuất sản phẩm
Các nền tảng như Netflix, Amazon và Spotify sử dụng học không giám sát để phân tích hành vi người dùng và đề xuất nội dung hoặc sản phẩm phù hợp.
– Xử lý hình ảnh và thị giác máy tính
Trong lĩnh vực thị giác máy tính, học không giám sát được sử dụng để phân đoạn hình ảnh, nhận dạng đối tượng và phát hiện các mẫu trong dữ liệu hình ảnh.
– Phân tích dữ liệu genomic
Trong nghiên cứu y sinh, học không giám sát giúp phân tích dữ liệu genomic để phát hiện các mẫu gene liên quan đến bệnh tật và phát triển các phương pháp điều trị mới.
Tương lai của Unsupervised Learning trong công nghệ hiện đại
Trong bối cảnh công nghệ phát triển nhanh chóng, tương lai của Unsupervised Learning đang rất hứa hẹn:
- Kết hợp với học sâu (Deep Learning)
Sự kết hợp giữa học không giám sát và học sâu đang tạo ra những tiến bộ đáng kể, đặc biệt trong các mô hình như Generative Adversarial Networks (GANs) và Variational Autoencoders (VAEs).
- Học bán giám sát (Semi-supervised Learning)
Phương pháp kết hợp giữa học có giám sát và không giám sát, sử dụng cả dữ liệu có nhãn và không nhãn, đang trở nên phổ biến và hiệu quả hơn.
- Học tự giám sát (Self-supervised Learning)
Một xu hướng mới nổi, trong đó mô hình tự tạo ra nhãn từ dữ liệu đầu vào, giúp khắc phục một số hạn chế của học không giám sát truyền thống.
- Ứng dụng trong các lĩnh vực mới
Học không giám sát đang được mở rộng sang nhiều lĩnh vực mới như y tế cá nhân hóa, thành phố thông minh, và tự động hóa công nghiệp.
Kết luận
Unsupervised Learning là một lĩnh vực quan trọng và đầy tiềm năng trong học máy, cho phép chúng ta khám phá và hiểu dữ liệu mà không cần gán nhãn trước.
Mặc dù có những thách thức nhất định, sự phát triển của các thuật toán và công cụ mới đang giúp học không giám sát trở nên dễ tiếp cận hơn cho cả chuyên gia và người mới bắt đầu.
Với vai trò ngày càng quan trọng trong kỷ nguyên dữ liệu lớn, học không giám sát chắc chắn sẽ tiếp tục phát triển và mở rộng trong tương lai.


